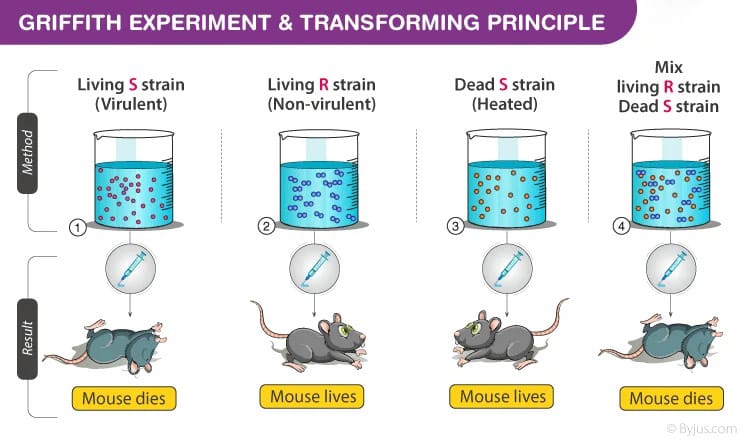
Primary databases play a crucial role in bioinformatics, serving as foundational repositories for raw, experimental data. These databases are indispensable for researchers in molecular biology, genetics, and computational biology, enabling them to access and analyze vast amounts of biological information.
Repositories of raw, experimental data collected directly from scientific experiments.
Typically unprocessed or minimally processed, ensuring data authenticity.
Serve as a reference for validation and further research.
Types of Primary Databases
Nucleotide Sequence Databases:
Contain DNA and RNA sequences.
Provide information on gene structure, function, and evolutionary relationships.
Examples: GenBank, EMBL-EBI, DDBJ.
Protein Sequence Databases:
Store protein sequences and related annotations.
Used for studying protein structure, function, and interactions.
Examples: UniProtKB, PIR (Protein Information Resource).
Genome Databases:
Focused on complete genome sequences.
Facilitate comparative genomics and evolutionary studies.
Examples: Ensembl, UCSC Genome Browser.
Protein Structure Databases:
Contain three-dimensional structures of proteins.
Provide insights into protein folding, interactions, and function.
Examples: Protein Data Bank (PDB).
Gene Expression Databases:
Archive gene expression data from various experiments, including microarrays and RNA-Seq.
Support functional genomics studies.
Examples: Gene Expression Omnibus (GEO), ArrayExpress.
Epigenomics Databases:
Include data on DNA methylation, histone modification, and chromatin structure.
Examples: Roadmap Epigenomics, ENCODE.
Metabolomics Databases:
Contain information on metabolites and metabolic pathways.
Examples: HMDB (Human Metabolome Database), KEGG.
Taxonomic Databases:
Catalog species and their classification.
Examples: NCBI Taxonomy, ITIS.
Examples of Primary Databases
GenBank:
Maintained by NCBI (National Center for Biotechnology Information).
Stores nucleotide sequences and their annotations.
UniProtKB:
Combines Swiss-Prot (manually curated) and TrEMBL (computationally annotated) protein data.
PDB:
Repository of 3D structural data for proteins, nucleic acids, and complex assemblies.
GEO:
Archives functional genomics data sets, focusing on gene expression.
DDBJ (DNA Data Bank of Japan):
Collaborative nucleotide sequence database for Asia.
Uses of Primary Databases
Data Access and Sharing:
Provide open access to global scientific data.
Promote collaborative research and innovation.
Molecular and Genetic Research:
Aid in gene identification and annotation.
Support studies of genetic variations and mutations.
Drug Discovery and Development:
Facilitate target identification and lead compound selection.
Help model interactions between proteins and potential drugs.
Evolutionary Biology:
Enable phylogenetic analysis and evolutionary tracking.
Support the study of conserved sequences and functional domains.
Systems Biology:
Integrate multi-omics data for understanding biological systems.
Support metabolic network reconstruction and simulation.
Education and Training:
Serve as resources for learning bioinformatics tools and techniques.
Provide datasets for computational biology projects.
Advantages of Primary Databases
Authenticity: Contain raw experimental data, ensuring reliability.
Accessibility: Freely available to researchers worldwide.
Integration: Often linked with secondary databases for enhanced data analysis.
Challenges in Using Primary Databases
Data Overload: Increasing volume of data can be overwhelming.
Standardization: Lack of uniform data formats may complicate analysis.
Data Curation: Quality control requires significant manual effort.
Conclusion
Primary databases are vital tools in bioinformatics, forming the backbone of biological data storage and sharing. They facilitate groundbreaking discoveries in genomics, proteomics, and systems biology while supporting the advancement of computational tools and techniques. Mastery of these resources is essential for researchers, educators, and students in the life sciences.












: Revolutionizing Pharmaceutical Discovery")